solr在windows下的安装及配置 |
您所在的位置:网站首页 › solr 使用 › solr在windows下的安装及配置 |
solr在windows下的安装及配置
|
最近接触搜索相关的内容,所以熟悉下solr的使用以及如何在java中使用solr实现搜索功能。 1、solr简介Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。 2、倒排索引有的人会疑惑,搜索通过数据库也能直接查到为什么还要solr这类搜索引擎。例如我现在要搜索"solr"相关的内容,通过数据库模糊匹配%solr%可以查到,数量少的话查询速度还挺可观,如果数据量到达百万级千万级甚至更多,可能查出来得猴年马月了。 而solr用的倒排索引可以解决这一问题。 什么是倒排索引,先说下正排索引。 假如我有部分数据 文档id 文档内容 1 solr的使用以及如何在java中使用solr实现搜索功能 2 solr是一个独立的企业级搜索应用服务器 3 倒排索引和正排索引 4 搜索引擎
假如我要搜索solr,通过正排索引就是文档id作为索引,找到内容包含solr的文档。文档数量多了之后极大增加的搜索时间。 而倒排索引是将文档内容分词后建立索引。 单词内容 文档id solr 1,2 java 1 搜索 1,2,4 索引 3 服务器 2
此时我要搜索solr时直接通过单词内容索引,找到文档id列表,在按照文档出现的频次等内容计算权重然后返回。 3、solr在windows下的安装与配置 3.1、solr的下载和安装前往官网下载solr,我下载的版本是solr7.7.2 http://lucene.apache.org/solr/ 解压后进入cmd进入bin目录执行 solr start命令,命令行显示如下,启动成功,默认端口8983,也可通过-p指定端口启动
此时可以打开solr管理页面,浏览器输入http://localhost:8983/solr
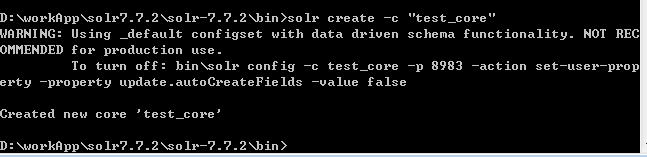
3.2 solr core的创建 core就是solr的一个实例,一个solr服务下可以有多个core,每个core下都有自己的索引库和与之相应的配置文件。命令行和管理页面都可以创建core,在这我通过命令行创建。 在命令行输入solr create -c "自定义core_name",如图创建成功。
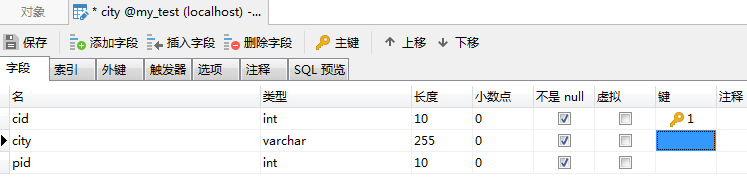
在mysql中添加表和数据,在这里我新增了表city,并添加了一些城市的数据。
在\server\solr\test_core(自定义的core名)\conf下新建dataConfig.xml (名字可以自己取)。 标签简介: dataSource:数据库连接的基本配置 entity:数据库中的表 field:表中字段与下文中配置的schema字段一致。 配置schema schema是用来告诉solr如何建立索引的,他的配置围绕着一个schema配置文件,这个配置文件决定着solr如何建立索引,每个字段的数据类型,分词方式等,新版本的schema配置文件的名字叫做managed-schema。 里面标签简介: fieldType:为field定义类型,最主要作用是定义分词器,分词器决定着如何从文档中检索关键字。 analyzer:他是fieldType下的子元素,分词器。 filed:创建索引用的字段,如果想要这个字段生成索引需要配置他的indexed属性为true,stored属性为true表示存储该索引。
在\server\solr\test_core(自定义的core名)\conf下打开managed-schema 配置数据导入处理器在\server\solr\test_core(自定义的core名)\conf下打开solrconfig.xml。添加以下内容,dataConfig,xml即为上文中配置的数据源。 dataConfig.xml导入jar包 数据库驱动的jar:mysql-connector-java-8.0.11.jar (注意这里jar包的版本要根据你数据库的版本来我的数据库是mysql8.0) data-import的jar:在根目录\dist下有这两个包solr-dataimporthandler-7.7.2.jar和solr-dataimporthandler-extras-7.7.2.jar。 复制这三个jar包到\server\solr-webapp\webapp\WEB-INF\lib下 导入数据以上配置结束后重新启动solr(命令行输入solr restart -p 8983)。登录solr管理页面http://localhost:8983/solr,可以看到选择core的时候可以选择之前创建的test_core
选择Dataimport选项,勾选clean、commit、 debug,Entiry选择city,点击Execute 执行成功后可以看见右边记录数,以及response下的具体数据。
关于solr管理平台的其他一些功能这里暂不详述,有兴趣的同学可以自行百度。 3.4查询选择Query功能,可以查询数据。
至此基本的查询已经实现了,但还没实现分词效果。 通过分词分析器可以看出这一句话没有分词。
配置ik分词器。下载ik-analyzer-solr7-7.x.jar,传送门 放入\server\solr-webapp\webapp\WEB-INF\lib中。 然后在WEB-INF文件夹下新建一个"classes"文件,从ik-analyzer-solr7-7.x.jar中找到配置文件IKAnalyzer.cfg.xml中赋值到classes目录下。(我是从jar包解压获取的)到classes目录下。然后配置managed-schema中添加ik分词器的配置,并且把field city的类型改为ik_word这样搜索的时候才会应用分词。
重启solr,打开管理界面分词分析,可以看到一句话被分成了好几个单词。
查询界面用这句话查询,可以看出查到了重庆市和北京市这两个记录。
至此分词查询也告一段落,下一章会和大家一起看看在java中使用solr。 4、相关问题Q&A Q:在Dataimport的页面下导入数据时,一直导入不成功,也看不到报错信息。A:勾选下列dubug选项,执行。右边会有具体报错信息,Unable to load authentication plugin 'caching_sha2_password'。
mysql-5.7版本是:default_authentication_plugin=mysql_native_password ,mysql-8.x版本是:default_authentication_plugin=caching_sha2_password 而mysql-connector-java-5.7.jar的版本识别不了mysql_native_password的密码规则,替换jar包为8.0.11即可。
本人只是个小白,以上只是个人拙见,如果有问题还请大家指出,有更好的想法欢迎大家留言,一起进步,谢谢! |











【本文地址】